AI Incident Management: How It Differs from Traditional ITIL
Category
Service Management
Uncategorized
.svg)
Category
AI incident management is the practice of using artificial intelligence, specifically predictive classification, context-aware routing, and cross-incident pattern detection, to handle the detection, triage, assignment, and resolution of IT incidents with significantly less human intervention at each step. It doesn't replace incident management. It replaces the manual bottlenecks that ITIL was never designed to eliminate.
Traditional ITIL incident management was built for a world where every step required a human decision. A user submits a ticket. An agent reads it, selects a category from a dropdown, picks a priority level, finds the right queue, and assigns it. That process works. It's also slow; manual triage alone averages 8–12 minutes per ticket according to industry research across MSP and enterprise IT environments. Multiply that by hundreds of incidents per week, and you're measuring a meaningful chunk of your team's capacity in triage, not resolution.
That's the bottleneck AI is actually solving. Not a philosophical shift, a very specific operational one.
ITIL incident management follows a sequence most IT professionals know by heart: log, classify, prioritize, assign, investigate, resolve, close. Document everything. The process is sound. It was designed to bring consistency to what had previously been chaos, and for organizations moving from ad hoc support to structured IT service management, it delivered exactly that.
The problem isn't the framework. The problem is that the framework assumes each step requires a human decision, and that assumption was reasonable in 2005. It's a bottleneck in 2026.
Here's what the sequence looks like in practice at most mid-enterprise IT teams today:
A user submits a ticket, often incomplete, vague, or misidentified. An agent opens it, reads the description, checks the user's device history in the CMDB (if the CMDB is current, which is often a separate problem), selects a category and subcategory from a list, assigns a priority level, identifies the right team or individual, and moves the ticket to their queue. That triage step alone consumes 8–12 minutes for a standard ticket and 15+ minutes when the issue is ambiguous or the CMDB record is stale.
By the time the ticket reaches the agent who will actually fix it, 15 to 30 minutes have passed. In a 200-ticket-per-day environment, that amounts to several engineer-hours of queue management before any resolution work begins.
The bigger issue is that ITIL's sequential model also means each step blocks the next. Classification has to happen before routing. Routing has to happen before investigation. Investigation has to happen before resolution. AI doesn't just speed up those steps; it runs several of them in parallel and, in some cases, completes resolution before a human has finished the classification step.
The clearest way to show this isn't a list of features; it's a comparison of the same incident handled two different ways.

The incident: A user submits a ticket: "I can't log in." No additional context.
Traditional ITIL path:
Time from submission to resolution: typically 2–4 hours, including queue wait time. If the ticket was miscategorized initially (which happens frequently; users describe symptoms, not causes), add another cycle of reassignment.
AI-native path:
Time from submission to resolution: under 10 minutes. Zero agent involvement.
The password reset example is deliberately straightforward; it's also the most common type of IT incident in most organizations. HDI's State of Tech Support research reports that password resets and access issues account for a significant share of L1 ticket volume across enterprise IT environments.
What changes with complex incidents isn't the replacement of human judgment; it's the elimination of the rote work that delays it. An AI-native platform classifies the incident, pulls the relevant CMDB context, surfaces the last five similar incidents and their resolutions, and presents all of that to the assigned engineer before they've said a word. The human starts at step 3 instead of step 1.
The pitch for "AI in ITSM" has been around since at least 2018. Most of what vendors called AI then was keyword matching wrapped in a rules engine. What's available now is categorically different, and the distinction matters when you're evaluating platforms.
1. Predictive classification before the user finishes typing
Modern AI incident management platforms use transformer-based NLP to begin classifying an incident as the user types the description. By the time they hit submit, the category, subcategory, and suggested priority are already populated. This isn't autocomplete; it's the model inferring intent from partial input, cross-referencing against historical incident patterns, and generating a classification confidence score. Misclassification rates drop significantly compared to user-selected categories. Users are notoriously bad at categorizing their own incidents; they describe symptoms, not causes.
2. CMDB-aware auto-routing
Legacy routing is skills-based: it matches keywords in the incident to skills in the queue. It doesn't know that the user's laptop is running a specific VPN client version with a known conflict, or that their primary application server is owned by the networking team rather than the applications team. AI-native routing pulls live CMDB context and routes based on actual configuration relationships, not keyword guesses. The incident lands in the right queue the first time, eliminating reassignment cycles that add hours to resolution time.
3. Cross-incident pattern detection
This is the capability that moves incident management into problem management territory. When three users submit tickets in the same hour with similar symptoms, authentication failures, VPN drops, slow application response, traditional ITSM handles them as three separate incidents. An AI-native platform detects the pattern, correlates the incidents, and surfaces a potential underlying problem before the fourth ticket arrives. That's the difference between reactive firefighting and getting ahead of a service-affecting issue before it affects 30 users instead of 3.
For anyone who has sat through a post-incident review and heard "we had seven tickets about this before we realized it was a network issue", this is the capability that eliminates that conversation.
4. Sentiment-aware escalation
AI platforms can analyze the language in an incident description and update records to flag emotional signals, frustration, urgency, language indicating a high-stakes situation, and adjust priority accordingly. A ticket that says "this is the third time this week" carries a different level of urgency than a first-occurrence report of the same technical issue. Traditional ITIL priority models don't capture that. AI can.
5. Post-incident knowledge generation
Every resolved incident contains institutional knowledge that most organizations fail to capture. The agent who fixed it knows what worked, but that rarely makes it into a searchable, discoverable knowledge article. AI-native platforms can generate a structured knowledge article draft from the resolution workflow, what the issue was, what was checked, what fixed it, and route it for quick approval before the ticket closes. Over time, this builds a self-healing knowledge base that reduces future resolution time for similar incidents.
I'm going to be straight with you here, because this is the part that most AI vendors skip.
We wrote about this honestly in our post on 7 AI use cases running in production right now, and the same principle applies here. AI incident management is genuinely valuable in specific, bounded scenarios. It is not a universal upgrade that improves every incident category.
Complex multi-system outages. When an incident spans five interdependent systems, has three possible root causes, and requires coordinated action across networking, applications, and infrastructure teams, that's not an AI-resolution scenario. That's a war room situation where AI's role is to provide context and surface relevant data quickly, not to drive the remediation. The engineers still have to be in the room.
Novel infrastructure failures. AI classifies and routes based on patterns in historical data. An incident type your organization has never seen before, a new application failure mode, a zero-day exploit, a first-occurrence hardware failure on a newly deployed system, has no historical pattern to match against. The AI will either misclassify it or route it generically. For novel failures, human judgment is irreplaceable. An experienced engineer, upon seeing a new error signature, will outperform any model trained on your historical ticket data.
Vendor-dependent issues. When resolution depends on a third-party vendor, a SaaS outage affecting your environment, an ISP issue, or a cloud provider incident, AI can identify the dependency and create the vendor notification, but it cannot resolve the incident. It can reduce the time to detection and documentation, but the remediation path runs through someone else's team.
Politically sensitive incidents. Some incidents aren't technically complex; they're organizationally complex. An executive's laptop issue. A compliance-related data access incident. A system failure tied to a recent change involving someone's name. These require human judgment about how to communicate, escalate, and document. AI can assist with documentation, but routing and handling decisions should stay with a senior human.
The organizations getting the most value from AI incident management are the ones that are clear-eyed about these boundaries and deploy AI where it demonstrably reduces resolution time, while keeping humans in the loop in scenarios where pattern-matching breaks down.
The following describes an AI-native incident lifecycle that covers both the standard path (AI handles the end-to-end process) and the escalation path (AI assists with human resolution). This will be available as a downloadable visual PDF; see the CTA below.
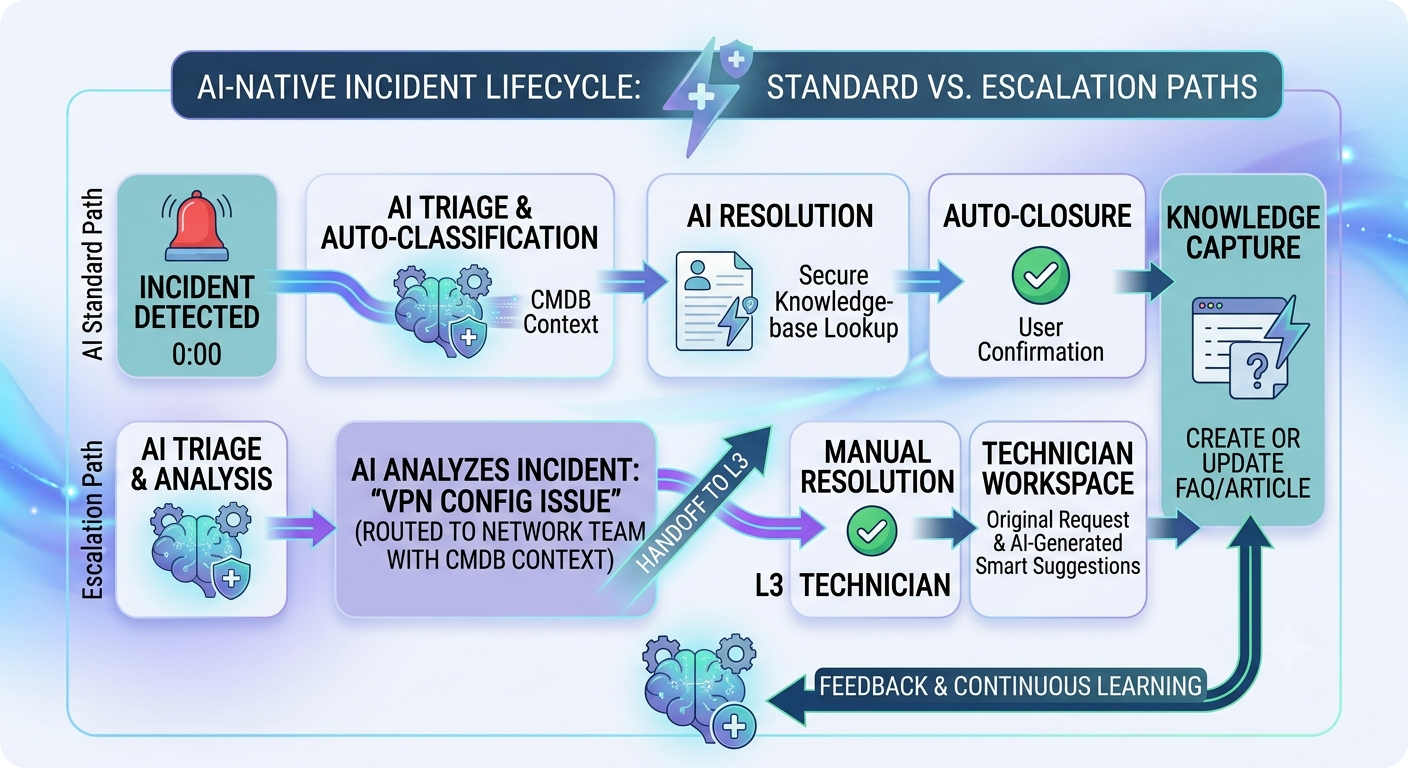
Standard Path, AI Handles End-to-End:
Step 1: Detection. Incident enters via user submission, monitoring tool alert (Datadog, Splunk, PagerDuty integration), or automated system event. AI begins classification in real time.
Step 2: Classification. The NLP model assigns a category, subcategory, and priority based on the description text and CMDB context. Confidence score generated. High-confidence classifications proceed automatically. Low-confidence classifications are flagged for human review.
Step 3: CMDB Enrichment. Platform queries CMDB to retrieve: affected user's device record, assigned applications, team ownership, recent change history on related CIs, and any open related incidents.
Step 4: Pattern Check. AI scans the last 72 hours of incident data for similar symptoms. If a pattern is detected, incidents are linked, and a problem record is created automatically.
Step 5: Routing. Incident auto-assigned to the correct resolver team or workflow based on CMDB ownership and skills matching. No manual queue selection.
Step 6: Resolution. For L1-automatable categories (password resets, access provisioning, common software errors, VPN reconnection), AI executes the resolution workflow directly. For L2/L3 incidents, AI surfaces the five most relevant past resolutions and CMDB context for the assigned engineer.
Step 7: Knowledge Capture. On resolution, AI generates a draft knowledge article from the resolution workflow. Routed to the resolver for a 60-second review and approval. Published to the knowledge base.
Step 8 , Closure. Ticket closed with auto-populated resolution notes. SLA compliance recorded. User satisfaction survey triggered.
Escalation Path, AI Assists Human Resolution:
Steps 1–5 are identical. At Step 6, the AI determines it cannot resolve the incident automatically, either due to low confidence, a novel failure pattern, or a cross-system complexity flag. The handoff includes:
The human resolver starts with complete context rather than a blank ticket. Post-resolution, knowledge capture and closure follow the same workflow.
The market is full of platforms claiming AI-native incident management. Most of them are not. They are legacy ITSM platforms with an LLM bolted on top, what I'd call lipstick on a pig. The AI can summarize a ticket description, but it has no awareness of your CMDB, no access to your change history, and no ability to learn from your specific incident patterns. It's a general-purpose language model running alongside your ITSM, not inside it.
Here is what genuinely separates AI-native incident management from AI-assisted incident management:
Does the AI access your CMDB in real time? If the answer is "it pulls data once a day" or "it reads exported reports," the routing intelligence is operating on stale data. CMDB-aware routing requires live integration, not batch sync.
Does it learn from YOUR ticket history? Generic AI models are trained on public data. They have no idea that your organization's "Outlook connectivity" incidents are almost always caused by a specific pattern of authentication token expiry. Models trained on your historical incident data significantly outperform generic models in classification accuracy within 60–90 days of deployment.
What's the false positive rate on automated resolution? This is the question almost no vendor wants to answer. Every AI platform can tell you its resolution rate. Ask what percentage of AI-automated resolutions required a human to reopen the ticket. A 70% automation rate with a 15% false-positive rate is not a 70% automation rate; it's a 59.5% rate with additional user friction.
Can your team configure it without coding? If workflow changes require a ServiceNow developer or a professional services engagement every time, the AI layer is generating savings on one side of the ledger and consuming them on the other.
Does it integrate with your monitoring stack? Incident management doesn't start with a user ticket; it starts when something breaks. AI-native platforms receive alerts from Datadog, Splunk, PagerDuty, and similar monitoring tools and can open, classify, and route incidents from monitoring data before a user notices the problem.
For a broader look at how agentic AI is reshaping ITSM platforms, not just incident management, the agentic AI in ITSM guide goes deeper into the architectural differences.
And if you're evaluating whether your current platform's self-service capabilities are holding back incident deflection before tickets even reach the queue, the self-service portal overview outlines what a modern employee-facing portal should do automatically.
For a full look at what Servicely's AI-native ITSM platform handles, incident management and beyond, the ITSM solution overview has the details.
ITIL incident management is a sound process. It was designed to bring order to reactive IT chaos, and it did that. The problem isn't the framework; it's that the framework was built assuming humans would perform every step.
AI-native incident management doesn't throw out the ITIL process. It automates the rote decision-making within it, classification, routing, L1 resolution, and knowledge capture, so the process runs faster, with fewer handoffs, and with less manual overhead at every stage. The 71-hour median resolution time characteristic of manual ITSM environments drops to 4.4 hours. The 8–12 minutes of manual triage per ticket become a few seconds of AI classification. The post-incident knowledge article that never gets written becomes an auto-generated draft ready for 60-second approval.
For IT Operations Managers dealing with 200+ incidents per week, that's not a marginal improvement. That's a structural change in how the team spends its time.
Where it doesn't work yet- complex multi-system outages, novel failure patterns, politically sensitive escalations- it still reduces the overhead enough to let your team engage faster and with better context than they would have otherwise.
The question isn't whether AI changes incident management. It's whether your platform was built for it from the ground up or is running a language model on top of an architecture designed in 2008.
See how Servicely's AI-native platform handles incident management, from detection to knowledge capture, in a 30-minute demo tailored to your environment.
Dion Williams is the CEO and Founder of Servicely, an AI-native IT service management platform built for mid-enterprise organizations. Before founding Servicely, Dion led the ServiceNow reseller business that introduced ServiceNow to the Australian market, completing 400+ deployments before exiting in 2015. He built Servicely because he saw ServiceNow pricing out mid-market IT teams and AI coming out of the AI winter , and decided to build the platform he wished existed.
For a specific category of incidents, L1 resolutions like password resets, access provisioning, common application errors, and VPN reconnections, yes. AI-native platforms can handle these end-to-end without human intervention, and they account for a significant share of total incident volume across most organizations. For L2/L3 incidents involving complex multi-system dependencies or novel failure patterns, AI augments human resolution rather than replacing it. The realistic automation ceiling, for a well-configured AI-native platform, is 60–80% of incident volume by count, which is the majority of tickets, not all of them.
According to the Fixify 2026 IT Help Desk Benchmark Report, AI automation reduces median resolution time from 71 hours to 4.4 hours. Organizations deploying AI-native ITSM platforms typically report that AI handles 60–80% of L1 incident volume autonomously. The figure depends heavily on how well the AI is trained on your specific ticket history and how many L1-automatable incident types exist in your environment. Password resets, software access requests, and standard connectivity resets are the highest-volume automatable categories for most IT organizations.
Yes, AI incident management follows the ITIL incident management process. It doesn't replace the framework; it automates the manual steps within it. Classification, routing, escalation, resolution, and closure all still happen. The difference is that AI performs several of those steps faster and with less human intervention. ITIL 4 explicitly accommodates automation within the incident management practice. An AI-native platform that logs every automated action, maintains audit trails, and supports defined escalation paths is fully compatible with ITIL compliance requirements.
For a platform that learns from your historical ticket data, expect meaningful classification accuracy improvements within 60–90 days of deployment. The model needs sufficient ticket volume to identify your organization's specific patterns; most mid-enterprise IT environments generate enough incident data within that window. Platforms using general-purpose LLMs without fine-tuning on your data may perform adequately on common incident types from day one but will underperform on organization-specific patterns. Ask any vendor how their model is trained and whether it continues to learn post-deployment.
The clearest ROI is in resolution time and agent capacity. The Fixify 2026 report shows a 16x reduction in resolution time for AI-automated tickets (median: 4.4 hours vs 71 hours). If your cost per incident, including agent time, productivity loss, and escalation overhead, runs anywhere near the $25–$40 range cited in industry benchmarks, and you're handling hundreds of incidents per week, the math is straightforward. The second ROI lever is less visible: the capacity freed up by L1 triage and resolution returns to L2/L3 work and proactive problem management. Teams that automate L1 volume don't reduce headcount; they redirect it to work that actually reduces incident frequency.
It should. A genuinely AI-native platform integrates with your monitoring stack to receive alerts and open, classify, and route incidents from monitoring data before a user files a ticket. If a platform can only process user-submitted tickets, it's missing half the value. Integrations with Datadog, Splunk, PagerDuty, Dynatrace, and similar tools are standard in any serious AI incident management implementation. Verify that the integration is bidirectional: the platform should both receive alerts and push resolution status back to the monitoring tool.


.png)







