What we’ve learned from modernising high-growth service organisations
Category
Best Practices
Uncategorized
.svg)
Category
Over the last few years, we have had a front row seat to some of the biggest operational transformations happening inside high growth enterprises across the UK, Europe, Australia and the US.
We break down the biggest insights we have gained from modernising complex service operations at scale. What is working, what is breaking, and what it takes to build a service organisation that can truly scale itself, with real examples from our work across the industry.
The organisations that scaled the fastest did not start with AI. They started with visibility.
We see the same pattern across every transformation.
Operational pain is almost never caused by lack of demand. It is caused by lack of visibility.
One of our enterprise clients was a perfect example. Workloads were strong and teams were delivering, but leadership had no visibility over:
When they consolidated onto a unified operational platform and unlocked real time visibility, everything shifted.
This was not a tooling upgrade. It became the operating system that allowed automation, AI and resourcing to land properly.
Any organisation with multiple service streams can adopt this approach.
Visibility first. Optimisation second.
Across every enterprise we have worked with, one metric consistently determines service performance.
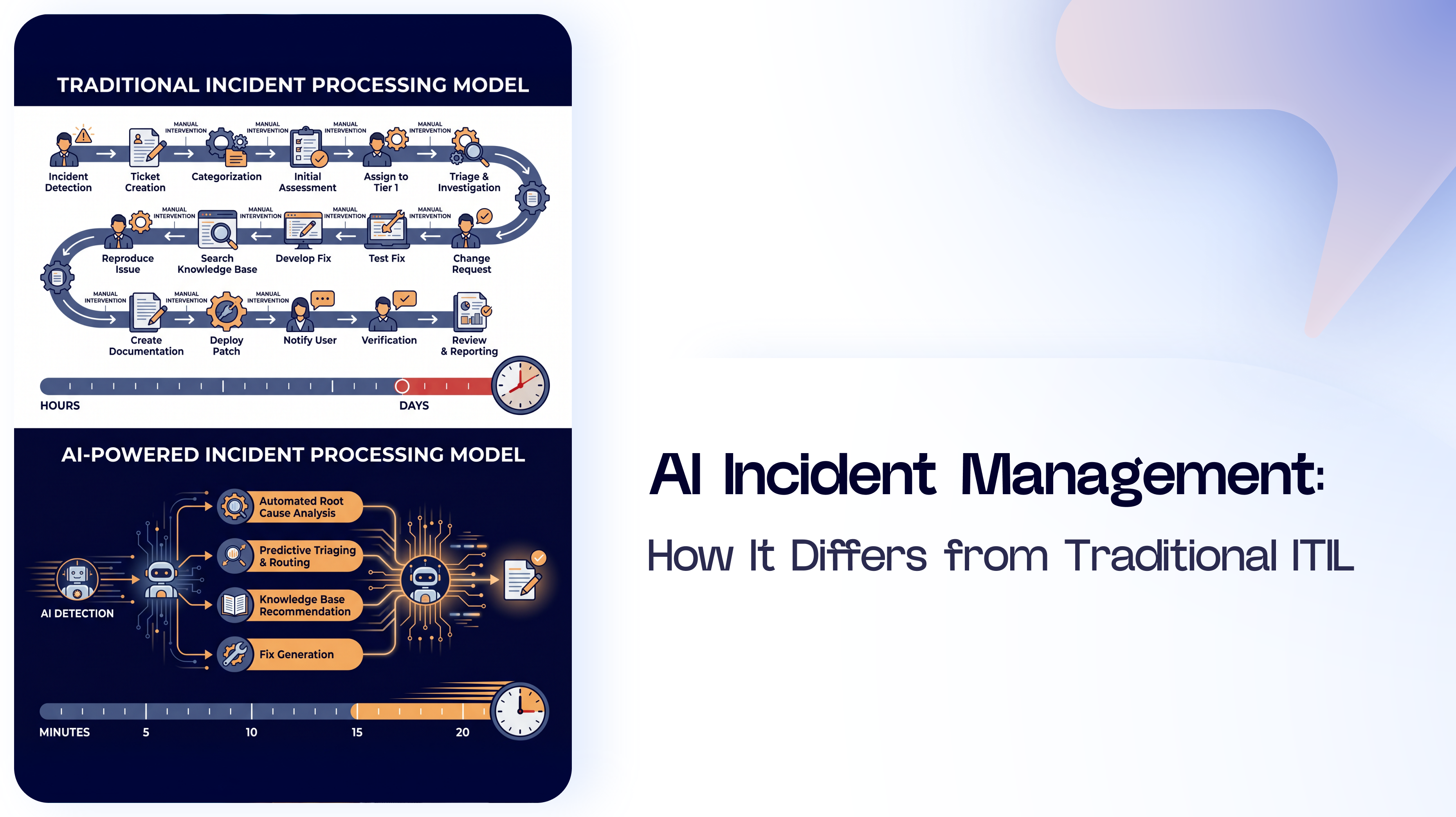
Classification speed and accuracy.
Before modernising, teams typically deal with:
After automated classification and routing:
If your organisation handles internal or external requests or incidents, this is one of the fastest operational improvements you can make.
Many organisations think they have a pricing problem when the real issue is fragmented operational data.
In one global enterprise we worked with, data was spread across multiple systems. Service lines were blended. High effort and low value work was hidden inside day to day operations.
After unifying their service desk, workforce data and reporting, they were able to:
Once leaders have accurate and real time operational data, profitability becomes a lever they can actually control.
Most enterprises underestimate the impact of manual time logging.
The average engineer or analyst loses 30 to 60 minutes a day to time entry admin.
Across a large team, this is thousands of hours a year and a significant margin impact.
Before modernising, we routinely see:
After unified time capture with AI assisted logging:
This remains one of the quickest ROI levers for any enterprise service organisation.
Across different industries, regions and maturity levels, the same blueprint appears.
The organisations that scaled fast and profitably had:
These lessons apply to any service organisation.
IT, field services, customer operations, shared services or hybrid teams.
The same operational mechanics apply.
If you are experiencing slow routing, unclear profitability, inconsistent SLAs, overloaded teams or a general sense that work is happening but you cannot see it, you are not alone.
Every growing organisation reaches this stage.
The difference is how quickly you move past it.
Start with visibility.
Fix classification.
Automate time.
Unify your data.
Then layer AI where it creates the most impact.
This is the blueprint we have applied inside service organisations globally.
It is the same foundation any enterprise can adopt today.
If you want to see how Agentic AI fits into this and how the system can move from surfacing insights to doing the work, you can watch our technical preview now.


.png)









